Causality Challenge #1: Causation and Prediction
The focus of this challenge is on predicting the results of actions performed by an external agent.
Examples of that problem are found, for instance, in the medical domain, where one needs to predict
the effect of a drug prior to administering it, or in econometrics, where one needs to predict the effect
of a new policy prior to issuing it. We focus on a given target variable to be predicted (e.g. health
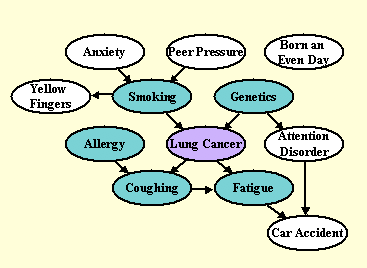
status of a patient) from a number of candidate predictive variables (e.g. risk factors in the medical domain). Under the actions of an external agent, variable predictive power and causality are tied together. For instance, both smoking and coughing may be predictive of lung cancer
(the target) in the absence of external intervention; however, prohibiting smoking (a possible cause) may prevent lung cancer, but
administering a cough medicine to stop coughing (a possible consequence) would not.
The challenge is over, but the platform is still open for post-challenge submissions.
Most feature selection algorithms emanating from machine learning do not seek to model
mechanisms: they do not attempt to uncover cause-effect relationships between feature and target.
This is justified because uncovering mechanisms is unnecessary for making good predictions
in a purely observational setting. Usually the samples in both the training and tests sets
are assumed to have been obtained by identically and independently sampling from the same
"natural" distribution.
In contrast, in this challenge, we investigate a setting in which the training and test
data are not necessarily identically distributed. For each task (e.g. REGED, SIDO, etc.), we have a single
training set, but several test sets (associated with the dataset name, e.g. REGED0, REGED1, and REGED2).
The training data come from a so-called "natural distribution", and the test data in version
zero of the task (e.g. REGED0) are also drawn from the same distribution. We call this
test set "unmanipulated test set". The test data from the two other versions of the task
(REGED1 and REGED2) are "manipulated test sets" resulting from interventions
of an external agent, which has "manipulated"
some or all the variables in a certain way. The effect of such manipulations is to disconnect the
manipulated variables from their natural causes. This may affect the predictive power of
a number of variables in the system, including the manipulated variables. Hence,
to obtain optimum predictions of the target variable, feature selection strategies should take into account such manipulations.
To gain a better understanding of the tasks, we invite you to study our toy example causal network for the model problem of diagnosis, prevention, and cure of lung cancer:
Competition rules
- Conditions of participation: Anybody who complies with the rules of the challenge
is welcome to participate. The challenge is part of the competition program of the
World Congress on Computational Intelligence (WCCI08),
Hong-Kong June 1-6, 2008. Participants are not required to attend the post-challenge
workshop, which will be held at the conference, and the workshop is open to non-challenge participants.
The proceedings of the competition will be published by the
Journal of Machine Learning Research (JMLR).
- Anonymity: All entrants must identify themselves with a valid email address, which will
be used for the sole purpose of communicating with them. Emails will not appear
on the result page. Name aliases are permitted during the development period to preserve anonymity.
For all final submissions, the entrants must identify themselves by their real names.
- Data: There are 4 datasets available (REGED, SIDO, CINA and MARTI), which have been progressively introduced, see the Dataset page. No new datasets will be introduced until the end of the challenge.
- Development period: Results must be submitted beween the start and the termination of the challenge
(the development period). The challenge starts on December 15, 2007 and is scheduled
to terminate on April 30, 2008.
- Submission method: The method of submission is via the form on the Submission page. To be ranked, submissions must comply with
the Instructions. A submission may include
results on one or several datasets. Please limit yourself to 5 submissions per day
maximum. If you encounter problems with the submission process, please contact the Challenge Webmaster.
- Ranking: For each entrant, only the last valid entry, as defined in the Instructions will count towards determining the winner. Valid entries are found in the Overall table.
The method of scoring is posted on the Evaluation page. If the scoring method changes, the participants will be notified
by email by the organizers.
- Reproducibility: Everything is allowed that is not explicitly forbidden.
We forbid using the test set for "learning from unlabeled data" [why?], that is for determining the structure and parameters of the model, including but not limited to learning variable causal dependencies from the test data, learning distribution shifts, and transduction. Participation is not conditioned on delivering your code nor publishing your methods. However, we will ask the top ranking participants to voluntarily cooperate to reproduce their results. This will include filling out a fact sheet about their methods and eventually participating to post-challenge tests and sending us their code, including the source code. The outcome of our attempt to reproduce your results will be published and add credibility to your results.