|
 |
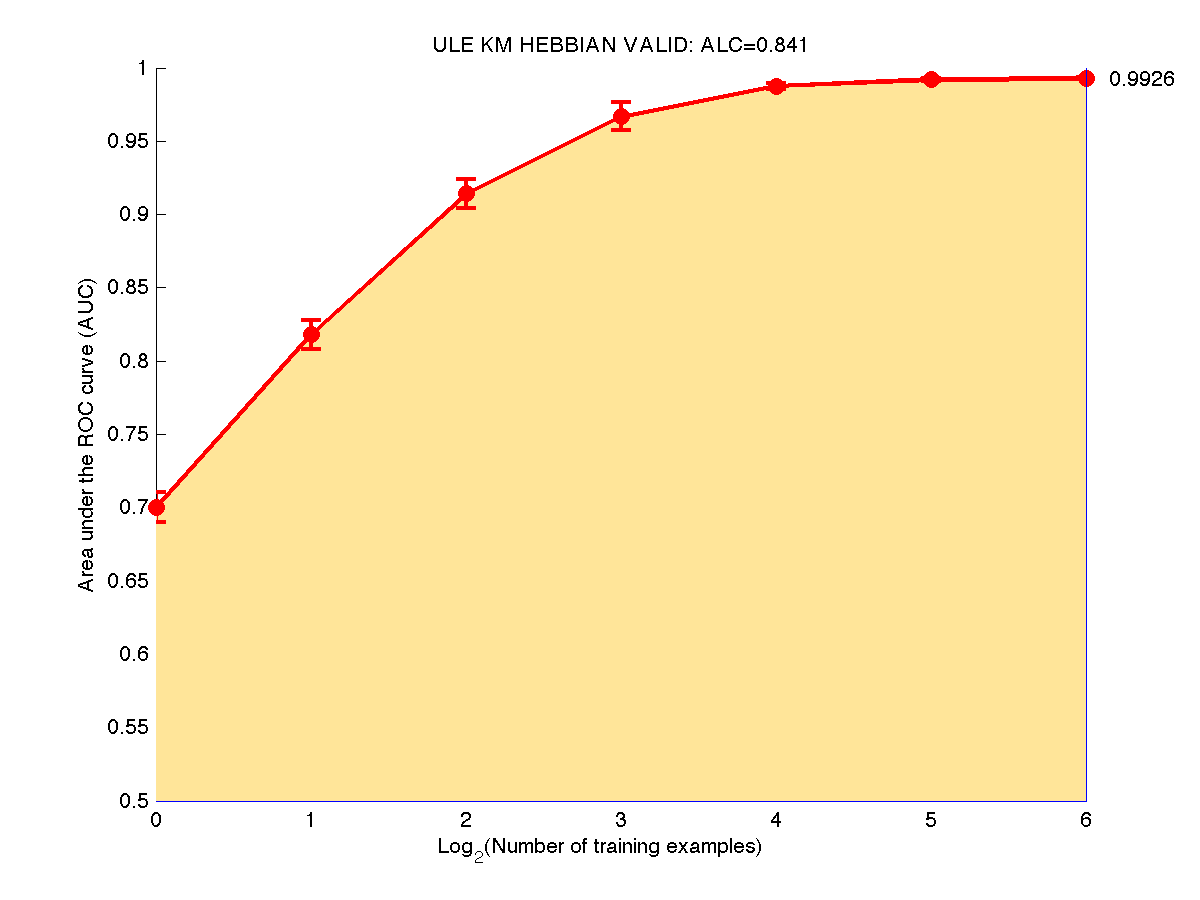
The prediction performance is evaluated according to the Area under the Learning Curve (ALC). A learning curve plots the Area Under the ROC curve (AUC) averaged over all the binary classification tasks and all evaluation data splits.
We consider two baseline learning curves:
global_score = ALC = (ALCraw - Arand)/(Amax - Arand)
We show below a learning curve for the toy example ULE, obtained using the sample code. Note that we interpolate linearly between points. The global score depends on how we scale the x-axis. Presently we use a log2 scaling for all development datasets.
The objective of the challenge is to make good predictions of the unknown values of a target variable (label) on a subset of the evaluation data called test set, when trained on the remainder of the evaluation data (the training set). The labels are binary (classification problem). One class is called "positive class" (label +1) and the other "negative class" (label 0 or -1, depending on the convention used). The linear classifier generates a discriminant value or prediction score.
The results of classification, obtained by thresholding the prediction score, may be represented in a confusion matrix, where tp (true positive), fn (false negative), tn (true negative) and fp (false positive) represent the number of examples falling into each possible outcome:
| Prediction | |||
|---|---|---|---|
| Class +1 | Class -1 | ||
| Truth | Class +1 | tp | fn |
| Class -1 | fp | tn | |
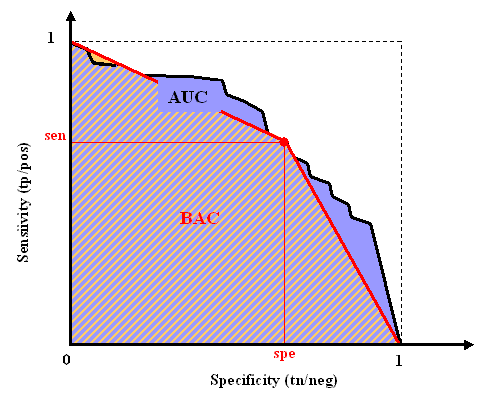
We define the sensitivity (also called true positive rate or hit rate) and the specificity (true negative rate)
as:
Sensitivity = tp/pos
Specificity = tn/neg
where pos=tp+fn is the total number of positive examples and neg=tn+fp the total number of negative examples.
The prediction results are evaluated with the so-called Area Under ROC Curve (AUC), which we refer to as AUC score, to distinguish it from the global score (normalized ALC). It corresponds to the area under the curve obtained by plotting sensitivity against specificity by varying a threshold on the prediction values to determine the classification result. The AUC is related to the area under the lift curve and the Gini index used in marketing (Gini=2 AUC -1). The AUC is calculated using the trapezoid method. In the case when binary scores are supplied for the classification instead of discriminant values, the curve is given by {(0,1),(tn/(tn+fp),tp/(tp+fn)),(1,0)} and the AUC is just the Balanced ACcuracy BAC.